
Using Threads for Parallelism
현대 기계들은 대부분 Multi Core Processor를 가지고 있다. Multi Core Processor의 기계들은 운영 체제 Kernel이 Single Core에 순차적으로 배치되는 것이 아니라 여러 Core에 Parallel로 Concurrent Thread를 Scheduling하기 대문에 이러한 기계에서 Concurrent 프로그램이 더 빨리 실행되는 경우가 많다. 이러한 Parallelism을 이용하는 것은 웹 서버, 데이터베이스 서버, 대형 과학 코드와 같은 응용 프로그램에서 매우 중요하며 웹 브라우저, 스프레드시트, 문서 프로세서와 같은 주류 응용 프로그램에서 점점 더 유용해지고 있다.
Exploiting parallel execution
- 지금까지 I/O 지연을 처리하기 위해 Thread를 사용했다.
ex) 한 Client가 다른 Thread를 지연시키는 것을 방지하기 위해 Client당 하나의 Thread를 생성 - Multi-core/Hyperthreaded CPU는 다른 점을 제공한다.
- 병렬로 실행되는 Thread에 작업 분산
- 독립적인 작업이 많을 경우, 자동으로 동작한다.
ex) 어플리케이션을 많이 실행하거나, 많은 Client를 service할때 - 코드를 작성하여 하나의 큰 작업을 더 빨리 진행할 수 있다.
=> Multiple 병렬 하위 작업을 구성함으로써 가능하다.
Hyperthreading이 가능하다는 것은 예를 들어, Multi-core -> core가 4개라고 한다면 Hyperthreading이 가능하다는 것은 운영체제가 보는 CPU의 개수는 8개로 보인다. 이것이 가능한 이유는 CPU안에 Instruction을 처리하는 Unit(PC, Reg)들을 동일하게 2개 복제해놓고 실제 계산하는 Functional Unit(load, store, ALU)을 공유할 수 있게 해주는 방식이다. Hyperthreading이 가능한 CPU에서 Functional Unit(load, store, ALU, FPU) 여러 개를 동시에 사용할 수 있게 하기 위해 Control 부분에 PC가 2개 있거나 Reg Set이 2개 있어서 Function들을 Interleaving하면서 불시에 사용할 수 있게 해주는 방법이다. 그렇게 함으로써 Multi-core에서 더 많은 CPU가 있는 것처럼 만든다. 물리적으로 더 많은 CPU의 성능을 내진 못하지만 Workload에 따라서 동일한 성능을 가능하게 한다. Multi-Core에서 Thread를 실행하게 되면 물리적으로, 병렬적으로 CPU에 각각 매핑돼서 실행이 가능하다. 가능한, Thread들끼리 독립적인 작업을 가지고 실행하게 한다.
그럼에도 불구하고, Thread간에 공유하는 데이터가 있어서 완전하고 Parallel하게 실행하기 어려운 부분이 있다.
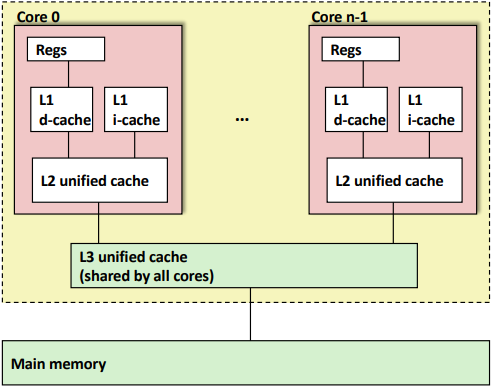
- CPU안에 여러 개의 Cache(SRAM)가 있다.
- L1과 L2는 Private Cache, L3는 Shared Cache라고 한다.
- L1과 L2는 자신의 CPU에서만 접근이 가능하고 L3를 통해서 다른 CPU와 공유가 가능하다.
- Access Latency: Reg > L1 > L2 > L3
- L1 Cache는 d-cache(Data)와 i-cache(Instruction)으로 나눈다.
Example 1: Parallel Summation
위 배경을 바탕으로 Parallel Summation 코드를 실행한 결과를 분석한다.
실행한 머신의 성능은 아래와 같다.
- Shark Machines
- Intel Xeon E5520 @ 2.27 GHz
- Nehalem, ca. 2010
- 8 Cores
- Each can do 2x hyperthreading
실험 내용은 아래와 같다.
- 0, ..., n-1까지 덧셈
- 1, ..., n-1까지 t라는 범위를 갖도록 Partition한다.
- 각 Thread마다 일부분의 덧셈을 하고 나중에 결과를 합산하는 방식
First attempt: psum-mutex
void *sum_mutex(void *vargp); /* Thread routine */
/* Global shared variables */
long gsum = 0; /* Global sum */
long nelems_per_thread; /* Number of elements to sum */
sem_t mutex; /* Mutex to protect global sum */
int main(int argc, char **argv) {
long i, nelems, log_nelems, nthreads, myid[MAXTHREADS];
pthread_t tid[MAXTHREADS];
/* Get input arguments */
nthreads = atoi(argv[1]);
log_nelems = atoi(argv[2]);
nelems = (1L << log_nelems);
nelems_per_thread = nelems / nthreads;
sem_init(&mutex, 0, 1);
/* Create peer threads and wait for them to finish */
for (i = 0; i < nthreads; i++) {
myid[i] = i;
Pthread_create(&tid[i], NULL, sum_mutex, &myid[i]);
}
for (i = 0; i < nthreads; i++)
Pthread_join(tid[i], NULL);
/* Check final answer */
if (gsum != (nelems * (nelems - 1)) / 2)
printf("Error: result=%ld\n", gsum);
exit(0);
}
/* Thread routine for psum-mutex.c */
void *sum_mutex(void *vargp) {
long myid = *((long *)vargp); /* Extract thread ID */
long start = myid * nelems_per_thread; /* Start element index */
long end = start + nelems_per_thread; /* End element index */
long i;
for (i = start; i < end; i++) {
P(&mutex);
gsum += i;
V(&mutex);
}
return NULL;
}첫 번째 방식은 여러 개의 Thread를 만들어 놓고 gsum이라는 전역 변수에 주기적으로 update하는 방식이다.
모든 Thread가 각자 실행해야 하는 범위까지 덧셈을 하고 gsum을 update한다.
psum-mutext Performance

Thread가 많을수록 점점 더 느려진다.
for (i = start; i < end; i++) {
P(&mutex);
gsum += i;
V(&mutex);
}mutex lock과 unlock에 대한 Overhead가 크기 때문에 느려진다.
Next Attempt: psum-array
각 Thread마다 배열의 공간에서 덧셈을 하고 Master Thread가 마지막에 배열의 모든 원소를 더한다.
/* Thread routine for psum-array.c */
void *sum_array(void *vargp) {
long myid = *((long *)vargp); /* Extract thread ID */
long start = myid * nelems_per_thread; /* Start element index */
long end = start + nelems_per_thread; /* End element index */
long i;
for (i = start; i < end; i++) {
psum[myid] += i;
}
return NULL;
}각 Thread마다 배열의 원소에서 작업을 하기 때문에 mutex가 필요 없다.
psum-array Performance
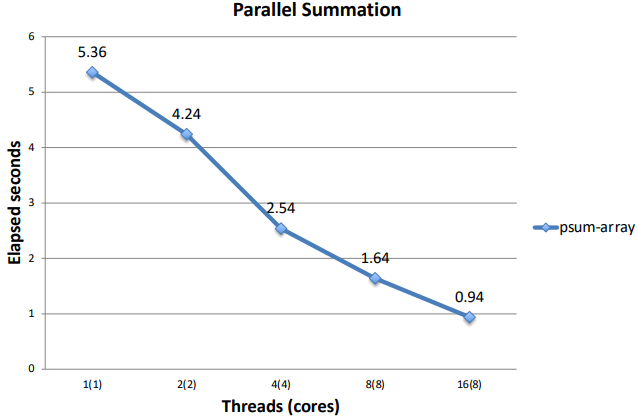
mutex를 이용한 방식보다 훨씬 성능이 좋아졌다.
Next Attempt: psum-local
/* Thread routine for psum-local.c */
void *sum_local(void *vargp) {
long myid = *((long *)vargp); /* Extract thread ID */
long start = myid * nelems_per_thread; /* Start element index */
long end = start + nelems_per_thread; /* End element index */
long i, sum = 0;
for (i = start; i < end; i++) {
sum += i;
}
psum[myid] = sum;
return NULL;
}배열을 전역 변수로 사용하는 것이 아니라 각 Thread가 지역 변수로 더한 값을 저장하는 방식이다.
Compiler가 Register에 있는 값을 Update할 수 있게 한다.
Peer Thread를 로컬 변수(register)로 합쳐서 메모리 참조를 감소시킨다.
결국 메모리가 아니라 Register에서 중간 값이 Update될 수 있다.
Thread 자신의 Reg에 Update하고 배열에 한번 씩만 덧셈한 결과를 저장한다.
psum-local Performance
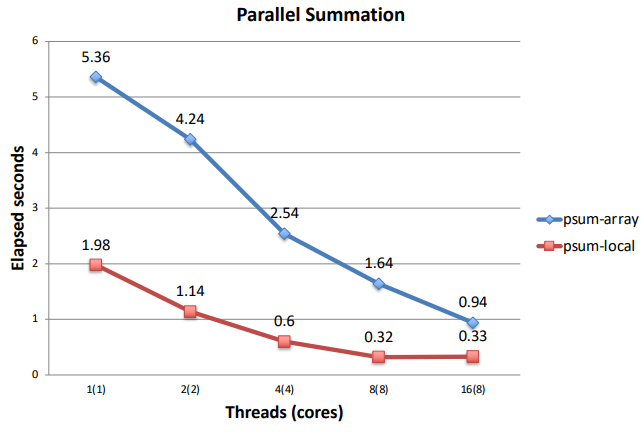
앞선 전역 변수로 배열을 사용하는 것보다 성능이 훨씬 좋아졌다.
Characterizing Parallel Program Performance
위 Parallel Sumation 예시로 Parallel 프로그램의 성능을 분석한다.
Processor core가 p개 있고, k개의 core를 사용하여 실행한 시간을 Tk라고 가정한다.
- Speedup: Sp = T1 / Tp
- Sp는 T1이 1 core에서 실행되는 코드의 병렬 버전 실행 시간인 경우 상대적인 Speedup이다.
- Sp는 T1이 1 core에서 실행되는 순차적 버전의 코드 실행 시간일 경우 절대적인 Speedup이다.
- 절대적인 Speedup은 병렬화의 이점에 대한 더 나은 척도이다.
- Efficiency: Ep = Sp / p = T1 / (pTp)
- 0 ~ 100 백분율로 보고된다.
- 병렬화로 인한 오버헤드 측정이다.
Performance of psum-local
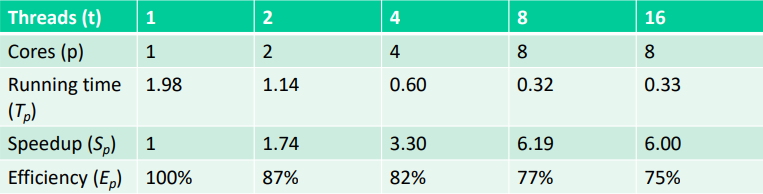
- Speedup
- core가 2개 일 때: T1 / T2 => 1.73...
- core가 4개 일 때: T1 / T3 => 3.3
- core가 8개 일 때: T1 / T4 => 6.19
- Efficiency
- core가 2개 일 때: T2 / S2 => 0.87...
- core가 4개 일 때: T4 / S4 => 0.82
- core가 8개 일 때: T8 / S8 => 0.77
Core를 더 증가시키면서 실행하면 효율성과 속도 향상이 떨어진다.
Memory Consistency
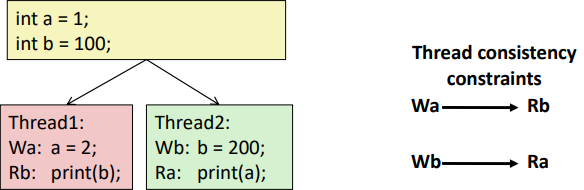
각 Thread마다 Excution Order는 정해져 있다.
하지만, 출력되는 a와 b가 원하지 않은 결과가 나올 수 있다.
Thread가 실행되는 순서가 Interleaving 될 수 있기 때문이다.
- 출력 가능한 값은 무엇인가?
- 출력되는 값은 Memory consistency 모델에 의존한다.
- 하드웨어가 Concurrent Access를 처리하는 방법에 대한 추상 모델에 따라 다르다.
- Sequential consistency
- 각 Thread는 일관된 진행 순서를 가진다.
- 그러나, Interleaving 될 수 있어 값이 Consistent하게 출력되지 않는다.
Memory Consistency Example
아래 그림은 출력 가능한 모든 경우의 수를 보여준다.
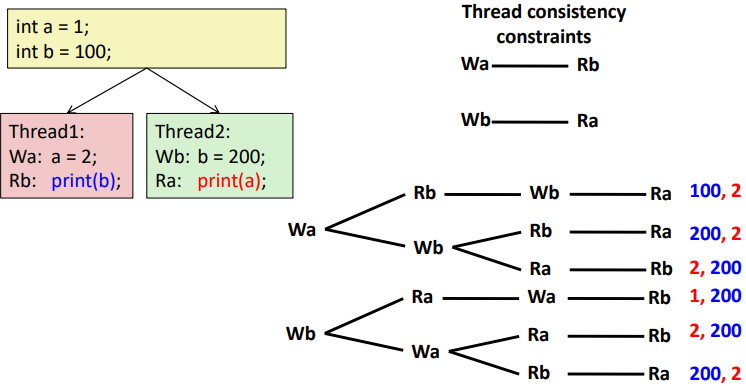
Thread마다 실행 순서는 정해져 있기 때문에 100, 1과 1, 100 은 출력될 수 없다.
Non-Coherent Cache Scenario
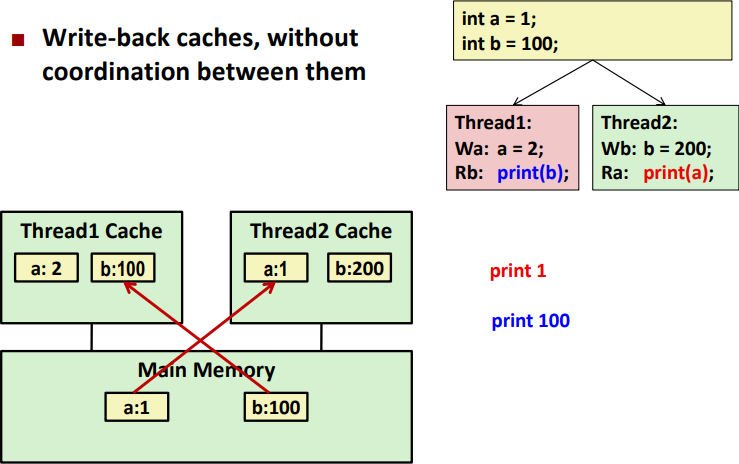
위 Memory Consistency Example과 달리 Cache를 염두하면 더 복잡해진다.
- Main Memory에서 a = 1, b = 100이다.
- Thread1이 Cache에서 a를 2로 바꾸고 Thread2가 Cache에서 b를 200으로 바꾼다.
- a와 b의 복사본이 각 Core의 Cache내에 a=2, b=200으로 존재한다.
- 그 값은 Main Memory에 있는 값과 다르다.
- Thread1과 Thread2는 a와 b의 복사본을 가지고 있고 각 Thread가 Cache에서 Update 했는데 Main Memory에 최종 Update를 하지 않은 상태이다.
- 그렇다면 Thread1은 b를 출력하면 Main Memory의 b = 100을 출력할 수밖에 없다.
- Thread1은 Thread2가 Cache에서 b = 200으로 바꾼 것을 알 수 없기 때문이다.
- 마찬가지로 Thread2가 a를 출력하면 a = 1을 출력할 수밖에 없다.
이렇게 출력하면 Consistency가 떨어진다.
Snoopy Caches
위 문제점을 보완한 것이 Snoopy Cache다.
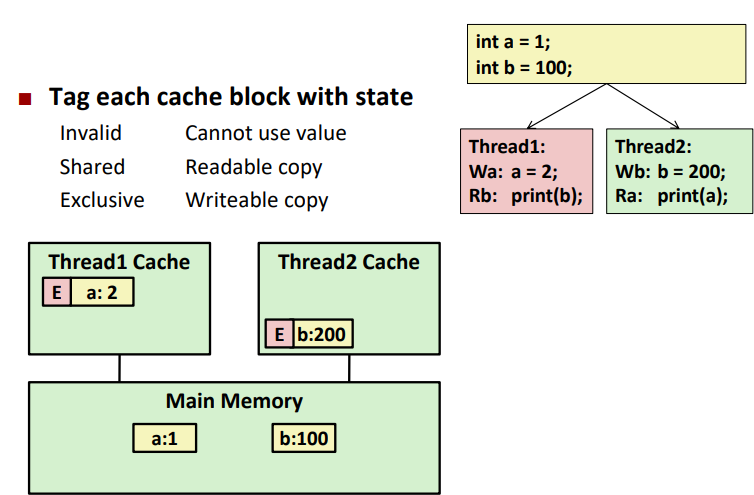
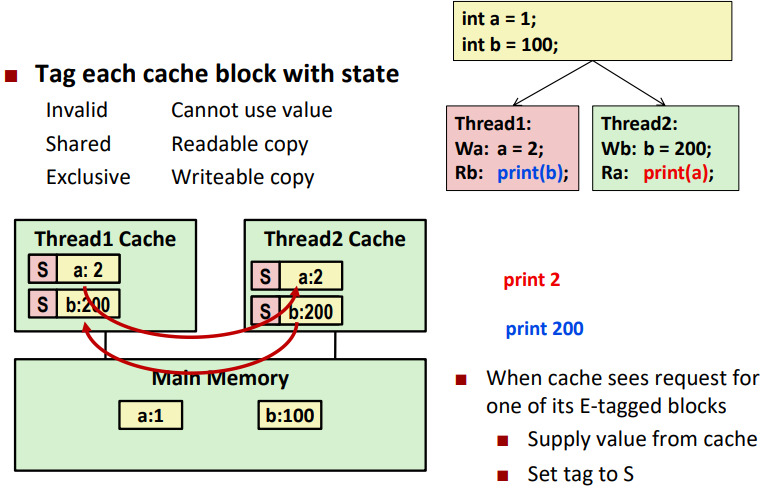
각각의 CPU의 Conent가 Caching될 때 Tag를 붙이는 방법이다.
- Exclusive: Main Memory에 Update가 안된 상태
- Shared: 다른 Core가 Content를 읽을 수 있는 상태
- Invalid: Content를 사용할 수 없는 상태
Core 사이에 어떤 내용과 어떤 Tag를 가지고 있는지 확인할 수 있는 방법이 하드웨어적으로 구현되어 있다.
하드웨어적으로 구현해놓았는데 그 Overhead로 인해서 성능 상 변화가 생길 수 있다.